
Spark Architecture – Notes & FAQ

I’ve spent the past couple of weeks trying to master the Spark Architecture and this post is a running summary of all my notes and questions gathered from across the internet & Stackoverflow. If you feel something is incorrect, I’ll be happy to discuss. Hope you find it useful!
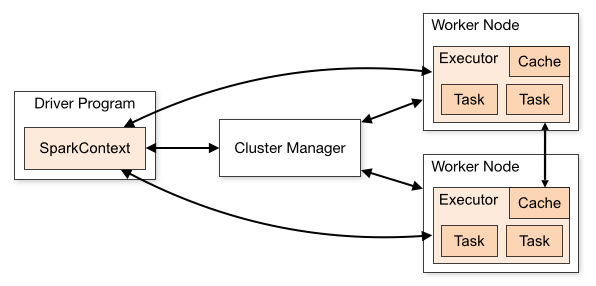
Node Machines and Worker Nodes
- A node is the actual physical machine. One node can contain the main driver while others will contain the workers.
- The diagram on Apache cluster docs shows a worker node and not the actual node. Though (as per https://spark.apache.org/docs/2.0.0-preview/spark-standalone.html) it is possible for a very large machine to have multiple “Worker” processes, it is generally recommended to have 1 worker per node. Therefore, the “Worker Node” reference is a fairly safe generalisation to make.
- If you do want to increase the number of workers per node, then the environment variable SPARK_WORKER_INSTANCES needs to be set.
SPARK_WORKER_INSTANCES | Number of worker instances to run on each machine (default: 1). You can make this more than 1 if you have have very large machines and would like multiple Spark worker processes. If you do set this, make sure to also set SPARK_WORKER_CORES explicitly to limit the cores per worker, or else each worker will try to use all the cores. |
Executors & Cores
- An executor is a process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors.
- A worker node can have multiple executors.
- Though executors are started within Worker Nodes, when executors are started they register themselves with the driver and they communicate directly with each other from that point on. The workers are in charge of communicating the cluster manager the availability of their resources. (Source).
- Each executor is a JVM instance.
- The number of cores in each executor determines the number of tasks that can run in parallel within the executor. So if we have 5 executors with 3 cores each, each executor should be able to run 3 tasks in parallel for a total of 15 parallel threads.
- Important – Research has found that 2-5 cores per executor is the right range to get optimal performance.
Questions:
Q. What metric determines the number of executors each worker can run?
A. This is determined based on the number of cores in a worker node. This is set using the --executor-cores flag or the spark.executor.cores property which determines the number of cores available per executor.
For e.g., Say worker node has 16 cores and 64 GB RAM. 1 core and 1 GB RAM is used by the OS. This leaves 15 cores and 63 GB RAM. If the --executor-cores is set to 3 , then the total number of executors in that worker will be 15/3 = 5.
Q. What does the --num-executors indicate then?
A. This indicates the total number of executors available to a Spark application. So from our earlier example, if we have a total of 5 worker nodes, the total executors will be 5*5 – 1 executor for the cluster manager = 24 executors.
An excellent answer by Ramzy in THIS PAGE dives into more examples around RAM and dynamic allocation.
Q. Can RAM and HD be allocated at an executor level? For e.g., if I have a worker node with 100GB of RAM and 5 TB HD, can I allocate 20 GB RAM and 1 TB HDD per executor for that worker?
A. RAM is allocated per executor but the hard disk space is at a worker node level and shared by all executors in the node.
Partitions, Executors and Tasks
- A partition is a portion of the actual data. This split could happen using hashing, round robin or range methods.
- The partitions could get located in a any executor. To co-locate data, repartition the data using the key which determines co-location
- The concept of co-location is important so that ‘Shuffles’ are reduced. Shuffles move data from one partition to another and incur network costs if these partitions are in different nodes.
- The maximum degree of parallelism that can be achieved is capped at the total number of partitions.
E.g., If you have a 5 node cluster with 3 executors each but only 2 partitions, only 2 executors are going to be doing something while the rest remain idle.
- If you have 5 executors in a node and each executor has 3 cores, then you can have a total of 15 tasks in parallel.
m = Number of executors per node
n = Number of cores per executor
p = Number of data partitions
c = Number of nodes in the cluster
Degree of parallelism = min(m*n*c, p)Jobs, Stages and Tasks
- Spark performs lazy evaluation which means nothing is executed till an action like read() or show() or collect() is performed.
- Behind the scenes, a DAG is created which split into Jobs, Stages and Tasks.
- Every spark application will have at least one job. Each job will have at least one stage and every stage will have at least one task.
- A job is created when there is an “Action”. If I have 2 actions, then there will be 2 jobs.
- A stage is created every time Spark has to perform a shuffle. This could be a result of operations like groupBy or join that require data to be shuffled.
- A task corresponds to the partitions being processed in the stage. If a stage is processing 5 partitions of data, you will have 5 tasks.
Q – So what happens if I have more partitions (tasks) than the number of executors* num of cores per executor?
A – The tasks will be queued by the executors and picked up once it finishes processing the current task.