
Real Time Data Streaming Into Kinesis & Ingestion Into Postgres Using AWS Glue – Part 1 (Setup)

This April, Amazon announced support for serverless streaming ETL using AWS Glue. For the uninformed – AWS Glue is built on top of Spark. Think of it as a fully managed Spark application with some unique ingredients of its own – namely, Dynamic Frames. The beauty of Spark is that it allows for handling data like a regular relational dataframe (Spark Dataframe, not to be confused with Pandas) while the data itself is truly distributed underneath. AWS Glue takes this and lays it on top of the powerful AWS ecosystem and what you get is a fully managed, scalable ETL service to build finely tuned data pipelines.
While I don’t intend to belittle nor glorify AWS Glue in this post, I strongly advise you to fully understand your use case before settling on AWS Glue. You should be able to find a lot of articles online and I will be writing one soon but to get started, just know that Glue is expensive, has start up times that may eat into SLAs and at this point, has a few constraints which I’m sure will be resolved as the technology evolves.
Now, getting to the point – I decided to take the new Real Time Streaming feature on a test drive and thought that my learnings were numerous enough to be penned down and saved for posterity.
As mentioned before, Glue is built on Spark. At its core is, well, Spark Core. On top of Spark core, you have Spark SQL, MLLib, GraphX and Spark Streaming.
Till April, Glue only allowed batch ETL which meant you could use Spark SQL, the Spark dataframes to do your processing but could never really use Spark Streaming. Now, you can create Glue Jobs that use Spark Streaming to continuously stream and transform data from a streaming source like Kinesis or Kafka. I setup a simple architecture to demonstrate these capabilities. The idea was to simulate an IoT stream that’s pushing data into a Kinesis stream. AWS Glue then picks up this data in real time and loads a Postgres table and archives into an S3 bucket.
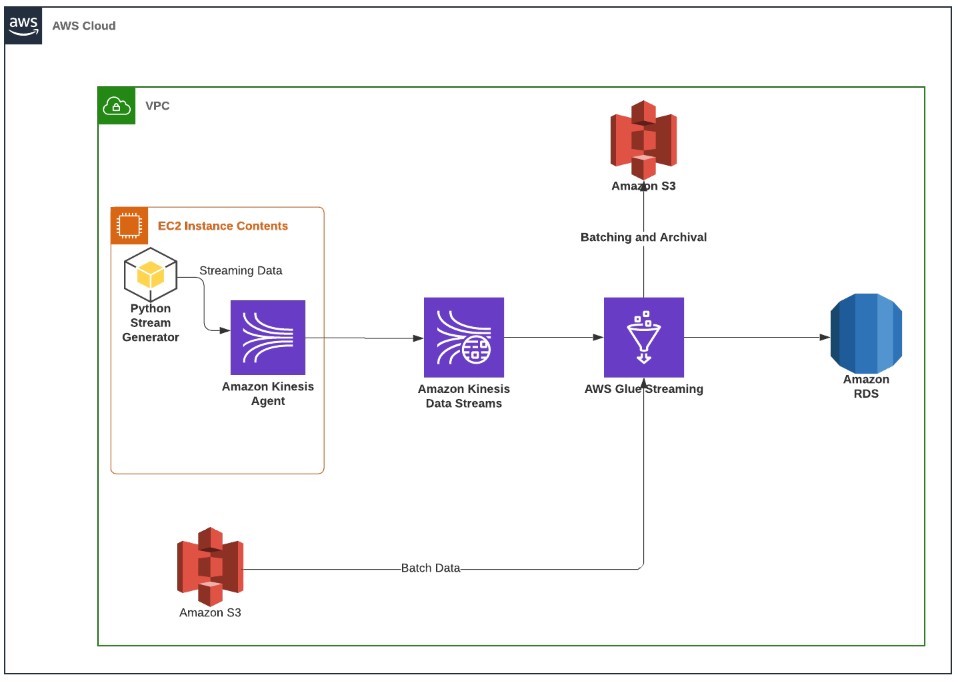
Note that this was strictly an academic exercise and I do not endorse Postgres or any relational DBMS to perform streaming analytics on IoT streams or big data of any kind.
Pre-requisites –
- An EC2 instance (T2.micro will do just fine) where we will configure the Kinesis agent and use as the stream source for this simulation
- Run this command to install the Kinesis Agent –
sudo yum install –y aws-kinesis-agent - Setup a log folder in your EC2 which your script will write into. This folder will be the location that the Kinesis agent monitors for new data.
Important – For some reason, the Kinesis Agent wasn’t able to monitor the folder if it was created under the home directory. So I created it under /tmp and everything went smooth from there on.
Step 1 – Setup IoT Stream Simulator:
This one was fairly straightforward. Github is littered with stream data generator scripts. Here’s the one I used :
The SourceFileName is the sample file containing all your JSON messages. NumOfLines indicates the number of messages you want to generate and stream. Subject area is just an added argument to use the same script for generating multiple streams.
Usage:
StreamGenerator.py SourceFileName.txt NumOfLines SubjectArea
#!/usr/bin/python
import sys, time
sourceData = sys.argv[1]
dataSubjectArea = sys.argv[3]
placeholder = "{}_LastLine.txt".format(dataSubjectArea)
def GetLineCount():
with open(sourceData) as f:
for i, l in enumerate(f):
pass
return i
def MakeLog(startLine, numLines):
destData = time.strftime("/tmp/aths-kinesis-stream/{}_%Y%m%d-%H%M%S.log".format(dataSubjectArea))
with open(sourceData, 'r') as jsonfile:
with open(destData, 'w+') as dstfile:
inputRow = 0
linesWritten = 0
for line in jsonfile:
inputRow += 1
if (inputRow > startLine):
dstfile.write(line)
linesWritten += 1
if (linesWritten >= numLines):
break
return linesWritten
numLines = 100
startLine = 0
if (len(sys.argv) > 1):
numLines = int(sys.argv[2])
try:
with open(placeholder, 'r') as f:
for line in f:
startLine = int(line)
except IOError:
startLine = 0
print("Writing " + str(numLines) + " lines starting at line " + str(startLine) + "\n")
totalLinesWritten = 0
linesInFile = GetLineCount()
while (totalLinesWritten < numLines):
linesWritten = MakeLog(startLine, numLines - totalLinesWritten)
totalLinesWritten += linesWritten
startLine += linesWritten
if (startLine >= linesInFile):
startLine = 0
print("Wrote " + str(totalLinesWritten) + " lines.\n")
with open(placeholder, 'w') as f:
f.write(str(startLine))Step 2: Setup the Kinesis Data Stream
- An EC2 instance (T2.micro will do just fine) where we will configure the Kinesis agent and use as the stream source for this simulation
- Run this command to install the Kinesis Agent –
sudo yum install –y aws-kinesis-agent - Setup a log folder in your EC2 which your script will write into. This folder will be the location that the Kinesis agent monitors for new data.
Step 3: Setup the Kinesis Agent
The primary objective of this exercise was not to test out the capabilities of Kinesis but those of Glue. So instead of writing a custom KPL, I used the Kinesis Agent (which uses the KPL behind the scenes) to simplify things and shift focus to Glue as soon as I could. For those interested, the agent.json config file must be configured to monitor the folder/files that the stream generator is creating. A sample agent.json is pasted below. Ensure that the kinesis endpoint is specified if your data stream is not in us-east-1. Also note the * to monitor all log files getting created. There are also several other transformation options available which can be found in the AWS Kinesis Documentation
{
"cloudwatch.emitMetrics": true,
"kinesis.endpoint": "https://kinesis.us-east-1.amazonaws.com",
"firehose.endpoint": "",
"flows": [
{
"filePattern": "FolderPath/*.log",
"kinesisStream": "KinesisDataStreamName",
"partitionKeyOption": "RANDOM"
}] }Step 4: Run your stream generator script
Head over to the Kinesis monitoring tab to see if data is being successfully streamed in. You can also view Kinesis Logs on your EC2 instance using the command:
tail -f /var/log/aws-kinesis-agent/aws-kinesis-agent.log
This concludes the initial setup and configuration. In the next post, we’ll walk through the actual AWS Glue code. Stay tuned!