
Understanding Driver Pools in Dataproc
Let’s learn about driver pools in Dataproc. But before we delve into the details of driver pools, it’s important to grasp why they are needed.
Therefore, let’s begin by understanding the reasons behind their very existence.
WHY DRIVER POOLS?
Consider a scenario where you have a Dataproc cluster utilized by a lone user. This user might execute occasional Hive queries, schedule batch Spark jobs, or maintain a relatively straightforward streaming pipeline on the cluster.
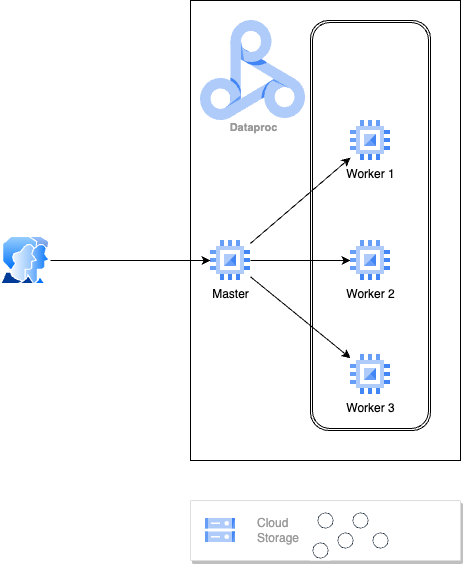
Let’s consider a scenario where the existing Dataproc cluster efficiently manages the regular workload using 3 worker nodes, with storage separated from compute in Google Cloud Storage (GCS). Now, let’s imagine it’s the holiday season, and there’s a sudden influx of source data, likely due to increased sales. During this peak period, Dataproc recognizes the heightened demand for additional memory or CPU resources. As a response, it dynamically expands the worker pool to cater to the surge in resource needs.
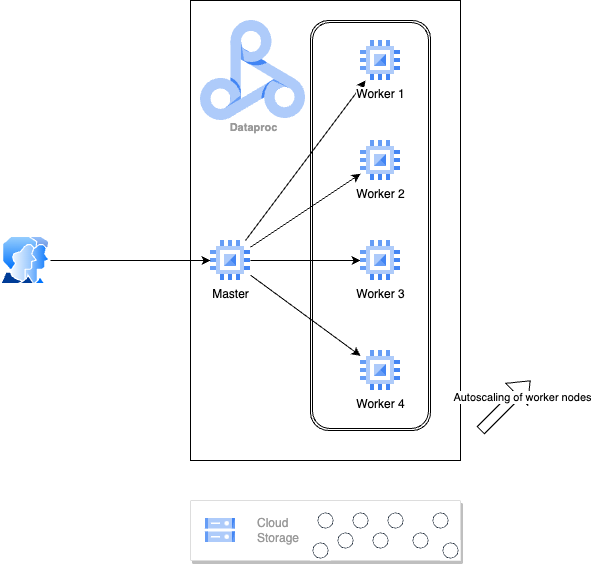
This allows you to focus on your application logic without worrying too much about the computing power of your underlying infrastructure. The more substantial the demand, the more expansive your cluster becomes, guaranteeing that your service level agreements (SLAs) remain unaffected by sudden workload spikes.
This form of elasticity is a well-known and documented feature in not just Dataproc but also in similar services across other cloud providers.
Now, let’s consider a slightly different type of surge. Imagine your data volumes remain constant, but there’s a notable rise in the number of concurrent users accessing the Dataproc cluster. Perhaps multiple data scientists have developed an interest in an ML model and are simultaneously conducting exploratory analysis on your data warehouse. What happens now?
If you think this is normal, you’re not alone. So, let’s try to understand the lifecycle of an application and some important terms necessary for this discussion. We’ll narrow down our focus in this article to Spark applications, although much of the fundamental principles could theoretically apply to other frameworks like Hive, Flink, Tez, and similar ones.
I’ve tried to keep it simple and provide you just enough information to understand the core subject of this article.
Driver:
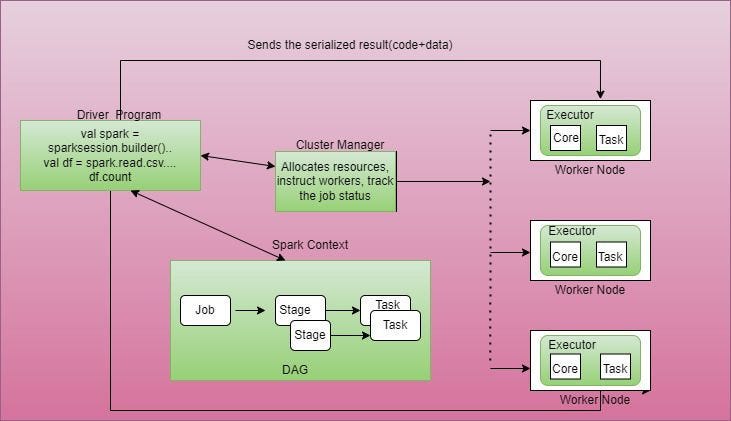
It’s a program that serves as the entry point for your application, manages the high-level control flow, and coordinates the execution of tasks across the cluster.
Key responsibilities of the Driver:
- Application Initialization: Define the processing logic & create tasks from the DAG
- Task Scheduling: Schedule tasks for execution on the available cluster resources (executors)
- Data Aggregation: For actions that require aggregating results across the cluster, such as
reduce()orcollect(), the driver collects and aggregates the results from all the tasks.
As you can see, the driver program is responsible for the distributed execution of your application, is the main entry point for your Spark program and also creates the SparkContext object.
Being responsible for all of this means that the driver program’s resource requirements are not constant. They increase with the data and complexity of the application and can also become the bottleneck for the application if not sized correctly or if enough resources aren’t available.
The Spark driver or any other framework’s driver for that matter runs on its own JVM which means that you have to allocate cores and memory that will be consumed from the node hosting the driver.
Application Master
- When an application is submitted to the cluster, the initial interaction occurs with the resource manager (like YARN) through the
spark-submitcommand. - The resource manager launches the application master, containerises it and schedules it on one of the nodes.
- The Application Master (AM) is responsible for negotiating resources with the cluster’s resource manager (e.g., YARN) and managing the lifecycle of Spark applications. It coordinates the allocation of resources for driver and executor components and monitors their progress.
The resource requirements of the application master itself are very modest and relatively constant as compared to the driver program.
Another important aspect in understanding drivers is Spark’s deployment modes. In the client mode which also happens to be Dataproc’s default spark.submit.deployMode for Spark applications, the driver runs in the client process, and the application master is used for negotiating resources with YARN. When using Dataproc jobs API and in any typical production scenario, the driver will run on the master node of the Dataproc cluster.
Also for Spark — The spark.yarn.unmanagedAM.enabledis set to True by default. Unmanaged here refers to the fact that the Spark application’s AM will not be scheduled in the Yarn cluster and will therefore NOT be managed by the Yarn resource manager. Instead Dataproc will run the AM within the driver process.
(Note that the MapReduce framework does not allow for unmanaged application masters and they will always be scheduled in a worker node.)
What happens when a job is submitted?
So now that we understand what drivers and application masters do and where they execute, let’s understand what happens when a user submits an application.
- When a user submits a job to a Dataproc cluster, the first handshake happens with the resource manager (say, YARN).
- YARN would then create an application master and from that point on, the application master will handle all resource negotiation for the application.
- The driver program gets launched in the master node using the driver size properties (cores and memory) specified at the time of submitting the job.
Now, going back to our question — what happens if there are multiple concurrent users or applications submitting jobs to the cluster?
While your worker nodes will stretch and squeeze to accommodate the compute needs, since the applications themselves start with the launching of a driver program on the master node, the number of driver programs on the master node begin to increase and the master node starts becoming a bottleneck. And not before long, the cluster will reach a stage where drivers may get starved of resources and consequently cause applications to fail. The dreaded kernel oom-killer may also kick in and kill driver processes when the master node’s physical memory starts getting scarce.
Also important to understand is that the master node is where the Hadoop cluster’s resource manager and namenode processes are running. When app drivers start overwhelming the master node, the entire cluster starts becoming unstable.
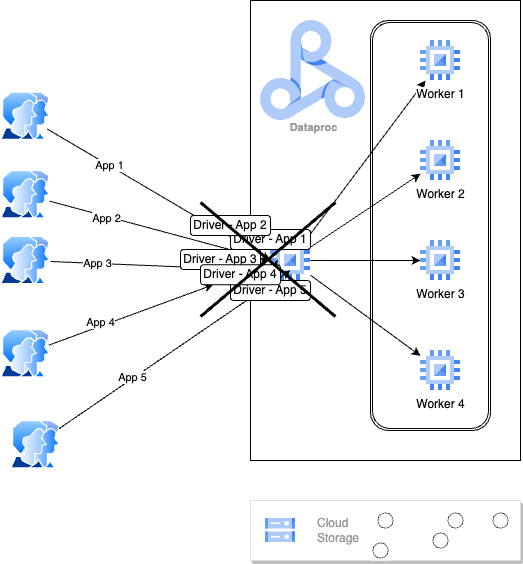
So, how do we solve this problem?
- The most straightforward way is to vertically scale the master node.
BUT this isn’t the most efficient solution since vertical scaling of the master node would require bringing down the cluster incurring a downtime and all other business related complexities.
- The other way to solve this would be to throttle the application scheduling such that they are more evenly spread out and the drivers don’t contend for resources. This page speaks about Dataproc APIs that can be used to throttle the concurrency, namely the
dataproc:dataproc.scheduler.max-concurrent-jobsproperty.
BUT this would mean sacrificing performance, overall latency & compromising on SLAs.
- Use
spark.submit.deplyMode=clusterthat schedules the driver program inside the app master on a container within one of the worker nodes.
BUT this would mean a very slow scale down. For large customers, efficient scale-down is a critical requirement from a cost optimisation POV.
- Cue, DRIVER POOLS!
What are Driver Pools?
A Dataproc Driver Pool is a pool of nodes within a Dataproc cluster that are dedicated to run job drivers.
These driver pools leverage the underlying concept of a NodeGroup in Dataproc and are essentially a cluster resource. A driver pool is associated with exactly one cluster. Driver pools must be defined at cluster creation time and their lifespan is limited to the lifespan of the cluster itself.
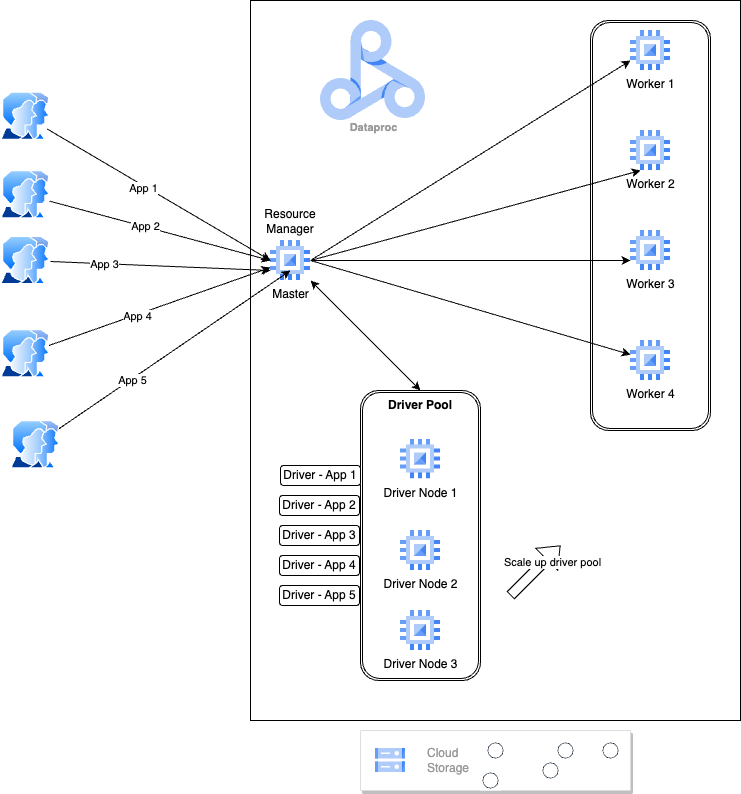
As depicted in the diagram above, the master node is relieved of the task of executing app drivers as this role is assigned to the driver pool. If there’s a need to enhance concurrency, the solution is as simple as augmenting the nodes within the driver pool. This expansion can be accomplished without concerns about throttling or vertical scaling, thereby ensuring seamless scalability.
How to Use Driver Pools?
- Define and create the driver pool while creating the cluster
gcloud dataproc clusters create demo-cluster-with-driver-pools \
--region=us-central1 \
--driver-pool-size=5 \
--driver-pool-machine-type=n2d-standard-4 \
--num-driver-pool-local-ssds=2 \
--driver-pool-id=demo-poolAs of Aug 2023, driver pools have to be manually scaled/resized. So it is important that you have rough initial estimates to calculate a good starting figure for the pool size.
- The next step is to submit the job using the Dataproc Jobs API:
gcloud dataproc jobs submit spark \
--cluster=demo-cluster-with-driver-pools \
--region=us-central1 \
--driver-required-memory-mb=2048 \
--driver-required-vcores=2 \
--class=org.apache.spark.examples.SparkPi \
--jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \
-- 1000- If at any point, you feel the need for increased concurrency or the complexity and scale of existing jobs have outgrown your current driver sizes, simply resize the driver pool using the
gcloudcommand –
gcloud dataproc node-groups resize demo-pool \
--cluster=demo-cluster-with-driver-pools \
--region=us-central1 \
--size=10Can The Driver Pool Be Autoscaled?
While Dataproc doesn’t support autoscaling of the driver pool (as yet), you can use yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainersand/or yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBto monitor available memory in the pool.
As a temporary measure, a straightforward rule based on thresholds can be established to simulate a form of auto-scaling for the driver pool.
For example, a monitoring alert can be configured to send notifications to a designated Pub/Sub channel, such as:
fetch gce_instance
| metric 'custom.googleapis.com/yarn/DriverPoolsQueueMetrics/AvailableMB'
| group_by 30m, [value_AvailableMB_mean: mean(value.AvailableMB)]
| every 30m
| condition val() < 100A Cloud Function with a Pub/Sub trigger can then launch a driver pool update command like below —
gcloud dataproc node-groups resize demo-pool \
--cluster=demo-cluster-with-driver-pools \
--region=us-central1 \
--size=10
Summary
In this article, we explored the concept of driver pools in Dataproc, focusing on their significance and how they address various concurrency challenges. By delving into the “why” behind driver pools, we’ve established the need for such pools in managing fluctuating workloads. We looked at how driver pools optimize resource utilization by ensuring that the Spark driver programs are efficiently managed, even during scenarios of increased data volumes or concurrent user demands.
References
https://cloud.google.com/dataproc/docs/guides/node-groups/dataproc-driver-node-group