
Build your own Ask-Me-Anything using VertexAI + LangChain + Streamlit 🎯🎯🎯

Artificial Intelligence and more specifically, its “Generative” heir has experienced a golden year thus far. Generative AI has laid the platform to re-define how more than 75% of jobs have traditionally operated.
As a cloud data architect, I realised that GenAI is going to become a key component in enterprise solutions much sooner than later. The beauty of it is that there’s no one stack where this can be constrained to. From data generation to code generation to testing, design, documentation, security, GenAI could potentially have a role to play in different areas of a solution.
As has been the case with most, I jumped into the bandwagon and made an attempt to learn and implement a matchbox solution that I could proudly show-off while also getting my hands dirty with the different libraries and terminologies.
Introduction
In this blog, we’ll walk through the process of creating a custom search engine using VertexAI, Streamlit and Langchain. The app will allow users to specify the sitemap of a website, crawl the entire site based on the URLs in the sitemap, and use the information as a knowledge base to answer user queries. We’ll use VertexAI embeddings & language models to understand user queries and provide relevant and accurate responses.
Architecture
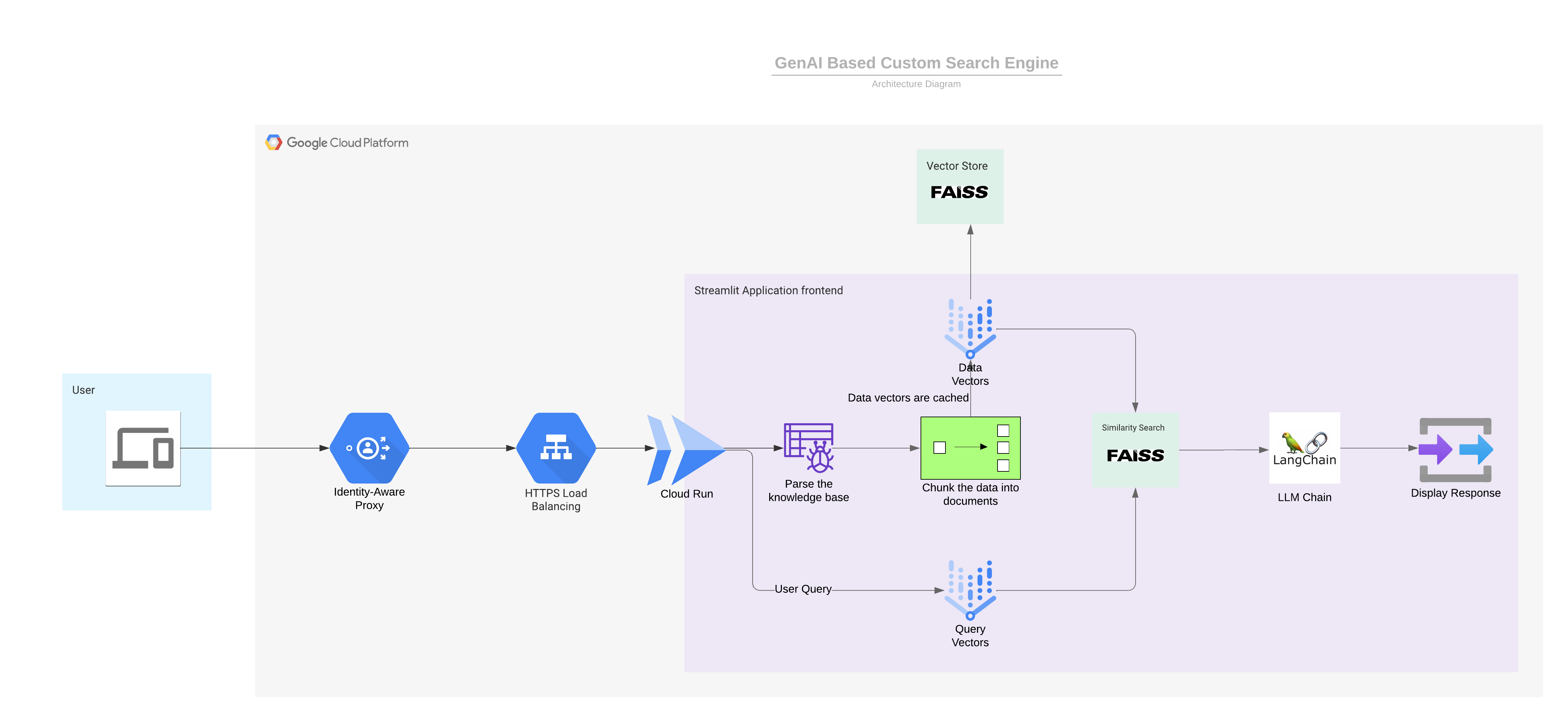
Let’s go through the design step by step to understand each part of the custom search engine.
Technologies Used
The following technologies were used to build the app:
1. Streamlit: Streamlit is an easy-to-use Python library for building web apps. It allows us to create interactive and data-driven web applications quickly.
2. Langchain: LangChain is a framework for developing applications powered by language models

3. VertexAI: We’ll use Google Cloud AI Platform to leverage the `textembedding-gecko` model for generating vector embeddings and generating summaries
4. FAISS: This is a library for semantic search and clustering of dense vectors.
1. Web Crawling and Document Retrieval
The primary input is the sitemap XML URL. We use the langchain library’s SitemapLoader to crawl the website and fetch all the documents. But this class isn’t very robust. It runs asyncio operations without regard for rate limiting on the server side. I’ve written a wrapper method which, if rate-limiting (429 error) occurs during crawling, retries up to a specified number of times with a backoff delay. It returns a list of document objects representing the website pages.
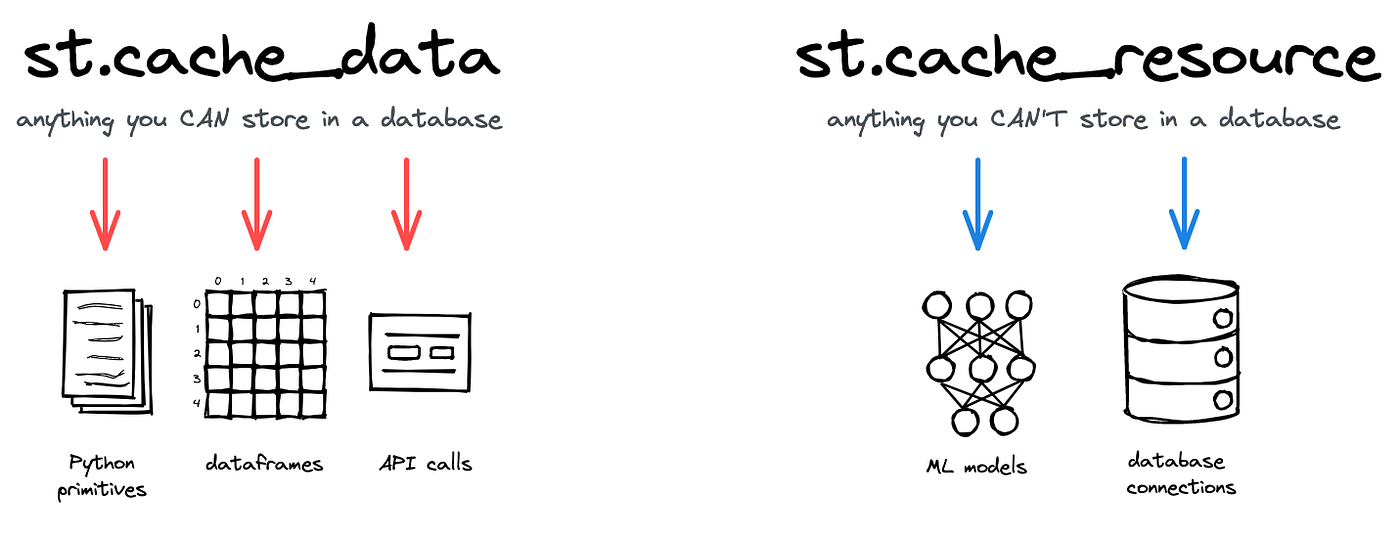
Further, I’ve used Streamlit’s caching mechanism to optimize the web crawling process since vector generation is an expensive and time-consuming process. I’ve usedst.cache_datato cache the pandas dataframes andst.cache_resourceto cache the vector embeddings. Read more about caching in Streamlit HERE
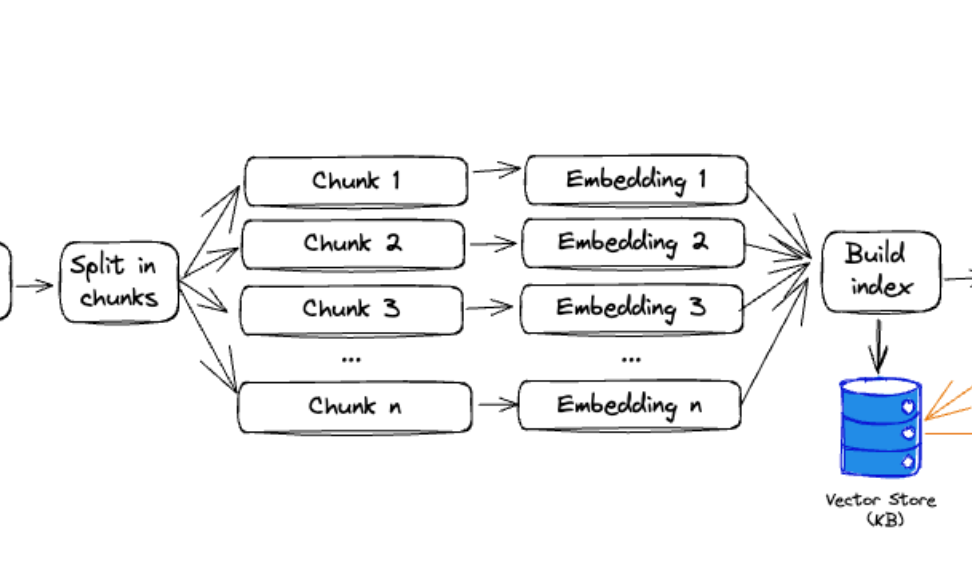
2. Embeddings Generation
Here we leverage `textembedding-gecko` model to generate vector embeddings for the crawled documents. The FAISS library is used to store the embeddings into a vector store locally.
An important aspect of this is the pre-processing step. In fact, calling this “Pre-processing” would be a grave injustice since the process of Splitting & Chunking is vital for the performance of the semantic search as well.
Chunking helps ensure that the embedding is devoid of noise while improving semantic relevance. There are several chunking/splitting strategies available. Here, I’ve used `CharacterTextSplitter`.
3. Fetching Possible Responses
We then use the vector embeddings generated earlier to perform a semantic search with the user’s query embeddings. It filters and retrieves documents with similarity scores above the specified threshold.
4. Generating Responses with Langchain
Finally, we utilize Langchain’s summarization and document retrieval capabilities to generate responses for the user’s query based on the filtered documents using VertexAI. Read more about the different kind of summarization chains offered by Langchain.
5. Hosting the app
The app was then containerised and hosted on GCP’s Cloud Run. I put the app behind an HTTPS load balancer to prevent any direct access to my Cloud Run service. The HTTPS load balancer was put behind IAP to prevent unauthorized or unathenticated users from accessing the app.
Look & Feel
Conclusion
You can find the full code and implementation details in my Github Repo at https://github.com/datasherlock/custom-genai-search-engine.
Please note that the implementation of the crawling and summarization processes can be further improved and customized based on specific requirements and use cases. Additionally, integrating more advanced NLP models and fine-tuning parameters may enhance the search engine’s performance and accuracy. This was merely an exercise in learning while trying to enjoy the journey!
Thanks for reading!