
Understanding CPU Oversubscription in Dataproc/Hadoop
Also published at https://medium.com/google-cloud/understanding-cpu-oversubscription-in-dataproc-hadoop-95eb92e4f45d
Let’s start by understanding 2 important properties in your Yarn configuration. For simple Hadoop workloads, it is best to leave these at their default values but if you are working with complex workloads that require fine-tuning of cluster resources for better cluster utilisation or more control over container scheduling, then continue reading.
yarn.nodemanager.resource.cpu-vcores :
Number of vcores that can be allocated for containers. This is used by the RM scheduler when allocating resources for containers. This is not used to limit the number of CPUs used by YARN containers.
yarn.scheduler.capacity.resource-calculator:
The ResourceCalculator implementation to be used to compare Resources in the scheduler. The default i.e. org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator only uses Memory while org.apache.hadoop.yarn.util.resource.DominantResourceCalculator uses Dominant-resource to compare multi-dimensional resources such as Memory & CPU to allocate containers.
An important thing to note is that the the cpu-vcores property will be ignored unless you set the capacity scheduler to use the
Source – https://hadoop.apache.org/docs/r3.1.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xmlorg.apache.hadoop.yarn.util.resource.DominantResourceCalculator.
What is Oversubscription of Cores?
“Yarn CPU Oversubscription” simply means setting the yarn.nodemanager.resource.cpu-vcores property to a value greater than the total vcores on a node.
For example —
Let’s assume that you have a Hadoop cluster stitched together with 10 GCE VMs where each GCE VM is an n2d-standard-48 machine.
This means that you have 48 virtual cores and 192 GB of memory per node for a total of 480 cores and 1.92 TB memory across the cluster.
( I’m of course simplifying the numbers here and ignoring the overheads which will take up a percentage of your actual resources.)
The value of yarn.nodemanager.resource.cpu-vcores when you create the cluster will be set to 48 to indicate that all 48 cores are available for containers to use. When you set this value to be greater than (>) 48, you are said to be over-subscribing the CPU.
What Happens When You Oversubscribe?
When the yarn.nodemanager.resource.cpu-vcores property is set to be greater than the total virtual cores, Yarn will tell the capacity scheduler that it has more virtual CPU cores than the node actually has available.
This can lead to overcommitment of CPU resources, as multiple YARN containers may be running on the same core at the same time. This can result in CPU contention and may cause performance degradation or even resource starvation for some applications.
I have even noticed that inordinate or unreasonable oversubscription causes nodes to hang and go unhealthy. So it is important to oversubscribe based on workload patterns and historical resource utilisation metrics.
It’s generally recommended to set the yarn.nodemanager.resource.cpu-vcores property to 80%-100% of the vcores in the node.
Let me explain with an example —
Let’s say we have 1000 containers each requesting for 1GB memory and 1 core.
An n2d-standard-48 machine has 48 virtual cores and 192 GB of memory. For simplicity, we will consider that 100% of the memory & CPU are available to the containers. Let yarn.nodemanager.resource.cpu-vcores=48
The total resources available in the cluster are:
10 nodes * 48 vcores per node = 480 vcores
10 nodes * 192 GB per node = 1920 GBGiven that each container is requesting 1 GB memory and 1 vcore, the total resource requirements for all 1000 containers are:
1000 containers * 1 GB memory per container = 1000 GB memory
1000 containers * 1 vcore per container = 1000 vcoresSince the total amount of memory requested by the containers (1000 GB) is less than the total amount of memory available in the cluster (1920 GB), memory is not a limiting factor.
However, since the total number of vcores requested by the containers (1000) is greater than the total number of vcores available in the cluster (480), vcores are a limiting factor. Therefore, not all containers can be scheduled to run concurrently.
A simple way to represent this would be through the concept of a Dominant Resource. Each container is asking for 1 GB which is
1/1920 = 0.05% of the total memorywhile the 1 core demand from each container translates to
1/480 = 0.2% of the total vcoresSince 0.2% > 0.05%, we can conclude that CPU is the dominant ask and will be the limiting factor
Scheduled containers = MIN (Actual Demand, Total Available Dominant Resource)
Schedule Containers = MIN ( 1000, 480 ) = 480 But let’s say that we know our workloads are not 100% CPU bound and that there’s some breathing room. We can then oversubscribe the available CPU by whatever factor best suits the workload. In our example, we can set yarn.nodemanager.resource.cpu-vcores=100. This results in the capacity scheduler assuming that it has 100 vcores * 10 nodes = 1000 vcores to work with. After the oversubscription,
Scheduled containers = MIN (Actual Demand, Total Available Dominant Resource)
Schedule Containers = MIN ( 1000, 1000 ) = 1000Are CPU cores magically added when I oversubscribe?
I wish! But no. CPU resources will be shared among all containers in a best-effort manner. Each container gets a fair share of the CPU. However, note that if all your containers are CPU bound and start demanding all of the CPU real estate, then your containers will get starved and may halt due to the resource contention. So, it is important to weigh the decision to oversubscribe very carefully based on your workload patterns.
This is a great article to understand CPU resources in Yarn clusters.
https://blog.cloudera.com/managing-cpu-resources-in-your-hadoop-yarn-clusters/
Does oversubscription affect the actual number of vcores allocated to an application?
Oversubscription does not change the actual number of virtual cores allocated to a YARN application.
Oversubscription occurs when the sum of the requested vcores across all running containers on a node exceeds the number of total vcores on that node. In this case, multiple containers may be running on the same core at the same time, but each container is still allocated only the requested number of vcores. If the containers are CPU bound, then the containers may have to wait for their share of the CPU and this will increase overall execution time of the application. The overall vcore-seconds metric may increase but not the actual vcores.
For e.g., in our examples above, say a heavily CPU bound application runs on 2 clusters — one with yarn.nodemanager.resource.cpu-vcores=48 and another with yarn.nodemanager.resource.cpu-vcores=100.
Say, that the application took 1 minutes on the first cluster and used 1000 vcores, then the vcore-seconds = 1000 * 60 = 60,000
Say, the application took 2 minutes on the 2nd cluster, it would still have used 1000 vcores overall but the vcore-seconds = 1000 * 120 = 120,000
Note that the variable is not the cpu-vcores but the execution time
Wondering How I Verified This?
- I created 2 demo clusters with 2 primary nodes of
n2d-standard-4each - On the first cluster, I set
yarn:yarn.nodemanager.resource.cpu-vcores=4which is equal to the vcores available in each node. - On the second cluster, I set
yarn:yarn.nodemanager.resource.cpu-vcores=16.I basically oversubscribed the CPU by 400%. This is NEVER recommended but since I knew the nature of my test job, I took the risk. - I submitted the
SparkPijob to both clusters with the number of Tasks set to 1000000. I chose this sample job since I know that it is moderately CPU bound and I will be able to demonstrate the CPU utilisation behaviour. - The first thing to note is the overall CPU utilisation of the job on both clusters which was more or less the same even though one of the clusters was oversubscribed by 400%
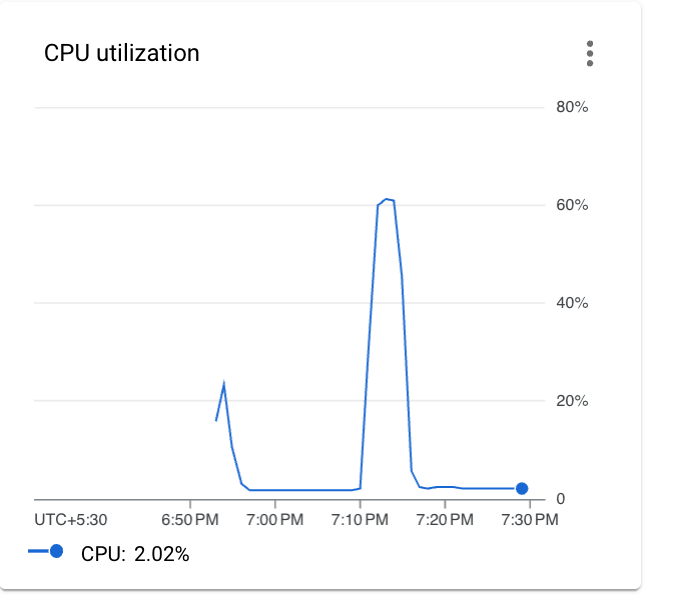
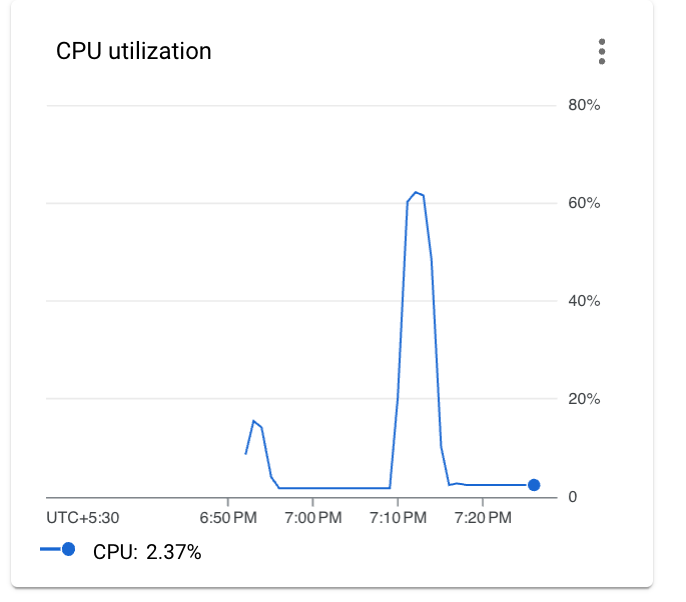
- The next thing are the actual performance metrics of the applications
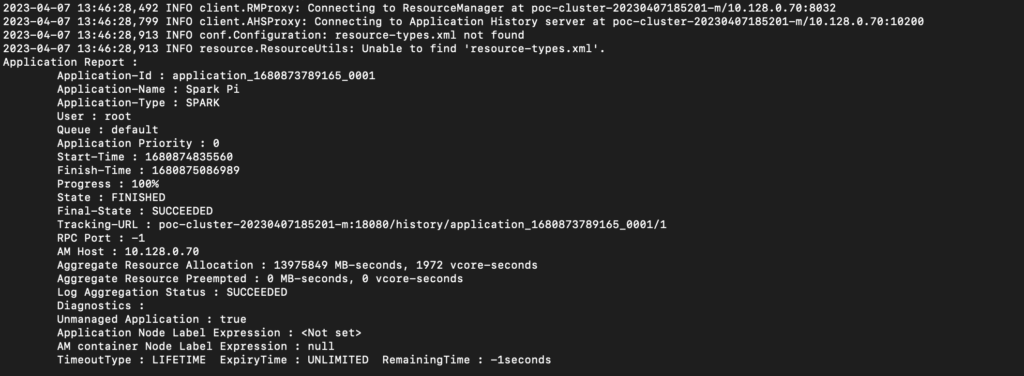
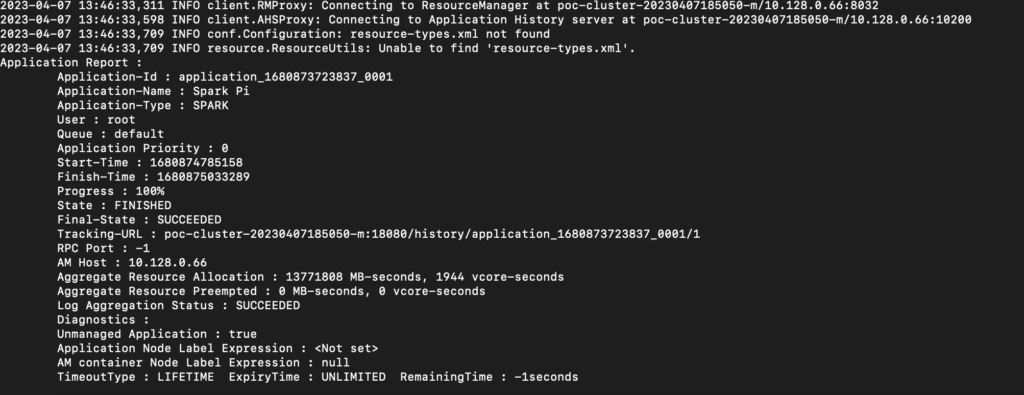
- The vcore-seconds are different because the over-subscribed cluster actually underperformed and took about 5 seconds longer to complete.
- The important thing to understand here is the below equation —
Actual vcores used = vcore-seconds/execution time
- If you do the math based on the numbers in the above screenshots, both applications consumed exactly 7.8 vcores irrespective of the oversubscription factor
What Are The Side Effects Of Oversubscribing?
Oversubscription can potentially lead to degraded performance, as CPU contention between containers can cause delays and reduced throughput. Therefore, it’s generally recommended to avoid oversubscribing CPU resources on YARN nodes and to set the cpu-vcores setting to a value that reflects the number of available virtual CPU cores on the node.
Isn’t DefaultResourceCalculator an extreme form of oversubscription?
In a sense, it is easy to assume that the DefaultResourceCalculator is a form of oversubscribing. But the reality is that this mode allows the containers to get all the CPU they need without explicitly constraining the allocation based on CPU cores. It essentially relies on the CPU scheduling policies of the underlying OS.
The DominantResourceCalculatoron the other hand uses DRF or Dominant Resource Fairness to allocate CPU as a first class resource. There is a fair amount of intelligence baked into this and there isn’t the same as a DefaultResourceCalculator
This is an excellent paper on Dominant Resource Fairness
When Does It Make Sense to Oversubscribe The CPU Cores?
A few use cases for oversubscription
- Workloads with short periods of high demand
- Moderately CPU bound workloads to improve overall CPU utilisation.
- Specific scenarios where you are encountering container flooding in nodes and need to control the container scheduling while ensuring optimal cluster utilisation.
Hope this article was informative and helpful. Please drop a comment with your feedback.