
Real Time Data Streaming Into Kinesis & Ingestion Into Postgres Using AWS Glue – Part 2 (Configure Glue Catalog Tables)

Before we start building Glue jobs, we need to understand that one of the unique features of Glue is its Catalog. A Data Catalog consists of:
- Databases
- Tables
- Connections
- Crawlers
You can configure crawlers to connect to data stores at both your sources and targets, parse through the metadata of the objects you want and create/update the metadata in the catalog.
These tables that the crawler maintains are under the Databases/Tables. You can schedule this crawler to periodically scan the data stores to check for metadata changes and make the required changes in the Glue Catalog.
Your Glue Jobs would use the catalog tables and because the metadata is managed in a separate layer, changes to metadata would typically not break your ETL jobs.
In our case, the Glue Catalog also plays an important role in connecting to a Kinesis Data Stream. Let’s see how –
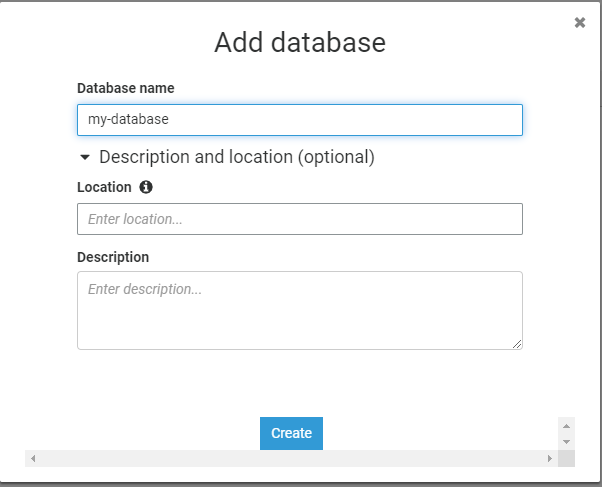
Step 1 – Add A Database
Head over to the AWS Glue service from the navigation menu and click on Databases in the left menu. Add a new Database. Leave the Location blank and give an appropriate description
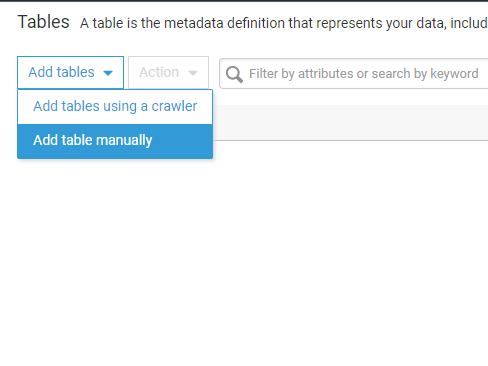
Step 2 – Add A Table
Then click on Tables and click on Add Table Manually from the dropdown menu
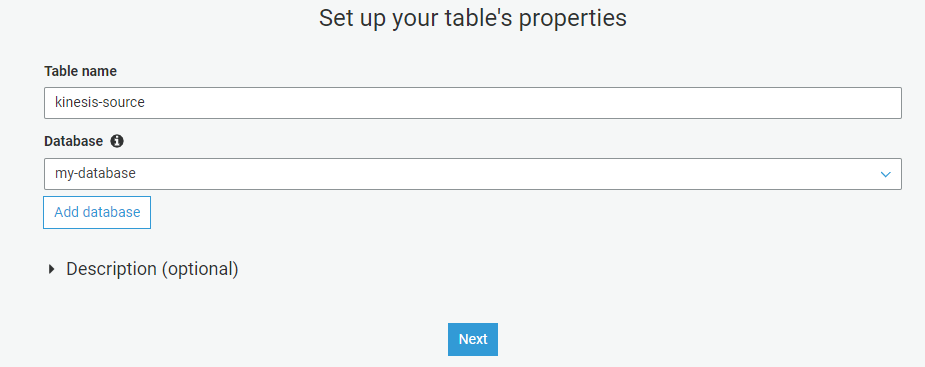
Give the table a meaningful name and click Next
This is the part where you will configure your connection to the Kinesis Stream. Choose the Kinesis radio button and provide the Stream Name and source URI
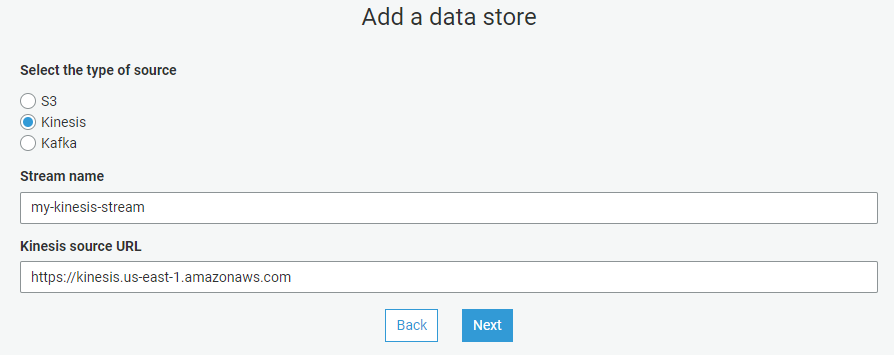
Note: If you are using a Kafka topic, you will need to do some additional prep work by first creating a “Connection” from the connections tab in Glue.
Then choose the data format of your source. In our case, this is going to be JSON. And finally define the metadata. Click Next and finish creating the table after reviewing your configurations on the final screen.
Step 3: Setup A Crawler For The Target Data Store
- Click on Connections and add a new JDBC connection
- Create a new Crawler
- Choose the Data Store type as JDBC
- Select the JDBC connection you created
- Select or Create an IAM role for the Glue service
- Choose a database where the crawler will create the tables
- Review, create and run the crawler
Once the crawler finishes running, it will read the metadata from your target RDS data store and create catalog tables in Glue.
So far – we have setup a crawler, catalog tables for the target store and a catalog table for reading the Kinesis Stream. In the previous post, we setup our EC2 instance and configured the Kinesis data stream.
In the next part, we’ll setup the AWS Glue Scripts that will perform the actual ETL.
Meanwhile, make sure you read my post on using Glue development endpoints